
Dead Letter Queues Explained: Handling Failed Messages
What a dead letter queue (DLQ) is, why messages end up there, and how to monitor, alert on, and reprocess them so failed events don't vanish silently.

Graceful Shutdown and SIGTERM: Deploy Without Dropping Requests
How graceful shutdown and SIGTERM handling let services finish in-flight requests during deploys and pod restarts, and how to avoid dropped connections.

Circuit Breaker Pattern: Failing Fast to Stay Resilient
How the circuit breaker pattern stops a failing dependency from cascading into a full outage: the closed, open, and half-open states, and what to monitor.

Retry Storms: Exponential Backoff and Jitter Explained
Why naive retries turn a blip into a retry storm, and how exponential backoff, jitter, and retry budgets stop a system from amplifying its own failures.

Alert Flapping: How to Tame Unstable Up/Down Alerts
What alert flapping is, why monitors flip between up and down, and how to stop the noise with confirmation checks, dampening, and multi-location verification.

Graceful Degradation: Designing Systems That Fail Well
What graceful degradation means, how it differs from fault tolerance, patterns like fallbacks and circuit breakers, and how to monitor a degrading system.

Idempotency Keys Explained: Safe Retries for APIs & Webhooks
What idempotency means, how idempotency keys make retries safe, exactly-once vs at-least-once delivery, and how to build reliable APIs and webhooks.

Chaos Engineering Explained: Breaking Things on Purpose
What chaos engineering is, how a controlled experiment works, the role of monitoring and blast radius, and how to start small without causing real outages.

The Four Golden Signals of Monitoring Explained
Latency, traffic, errors, and saturation — what Google's four golden signals mean, why they work, how to measure each one, and how to alert on them.

Incident Severity Levels: SEV1 to SEV5 Explained
What incident severity levels (SEV1–SEV5 / P1–P5) mean, how to define them, who they page, and how to classify incidents consistently under pressure.

RED vs USE Method: Monitoring Metrics Frameworks
RED (Rate, Errors, Duration) vs USE (Utilization, Saturation, Errors) — what each method measures, when to use which, and how they fit together.

10 Best Free Uptime Monitoring Tools in 2026 (Compared)
Compare the 10 best free uptime monitoring tools — check intervals, monitor limits, alert channels (email/Slack/SMS), and which free uptime monitor is right for you.

How to Evaluate a Vendor SLA: What to Look For
How to read and evaluate a vendor SLA before you sign — uptime definitions, service credits, exclusions, claim windows, and the questions to ask.

Cloud SLAs Compared: What AWS, Azure & GCP Actually Guarantee
Compare AWS, Azure and GCP uptime SLAs — what 99.9%, 99.95% and 99.99% really guarantee, how service credits work, and why the SLA is not your real uptime.

RTO vs RPO Explained: Setting Disaster Recovery Objectives
RTO vs RPO made clear — what each means, how they differ, how to calculate them, how they relate to MTD, MTTR and backups, and how monitoring protects both.

Cron Dead-Man Switch Monitoring: Catch Missed Jobs Fast
Detect cron and scheduled tasks that silently stop running. Build dead-man switches with last-success timestamps, grace periods, and missed-vs-failed alerts.
5xx Error Rate Monitoring: 500, 502, 503 Alert Guide
Track 5xx server error rates in production. Set alerts on 500, 502, 503 patterns and distinguish app bugs from infrastructure failures.

How to Reduce MTTR and Recover from Incidents Faster
Every minute of downtime costs money. Learn the 5 levers that reduce Mean Time to Recovery and how monitoring shortens each one.

Website Downtime Cost Calculator: What Every Minute Offline Really Costs
Use this downtime cost calculator framework to estimate lost revenue, support load, churn risk, and the real business impact of every minute offline.

Website Monitoring Checklist: What to Set Up Before an Outage
Use this website monitoring checklist to set up uptime, SSL, DNS, API, cron, alerting, and status page coverage before the next outage.
Multi-Tenant SaaS Monitoring: Per-Customer Uptime
Multi-tenant failures are hard to detect with global checks. Learn how to monitor per-customer uptime, isolate noisy neighbors, and alert by tier.

SLO Monitoring Guide: SLI, SLO, and Error Budget Explained
SLOs turn uptime goals into engineering decisions. Learn SLIs, SLOs, and error budgets, plus how to monitor them in production.

How to Choose a Website Monitoring Tool: The Complete Buyer's Guide
Not all monitoring tools are equal. This buyer's guide covers the features that matter, red flags to avoid, and how to find the right fit for your team.
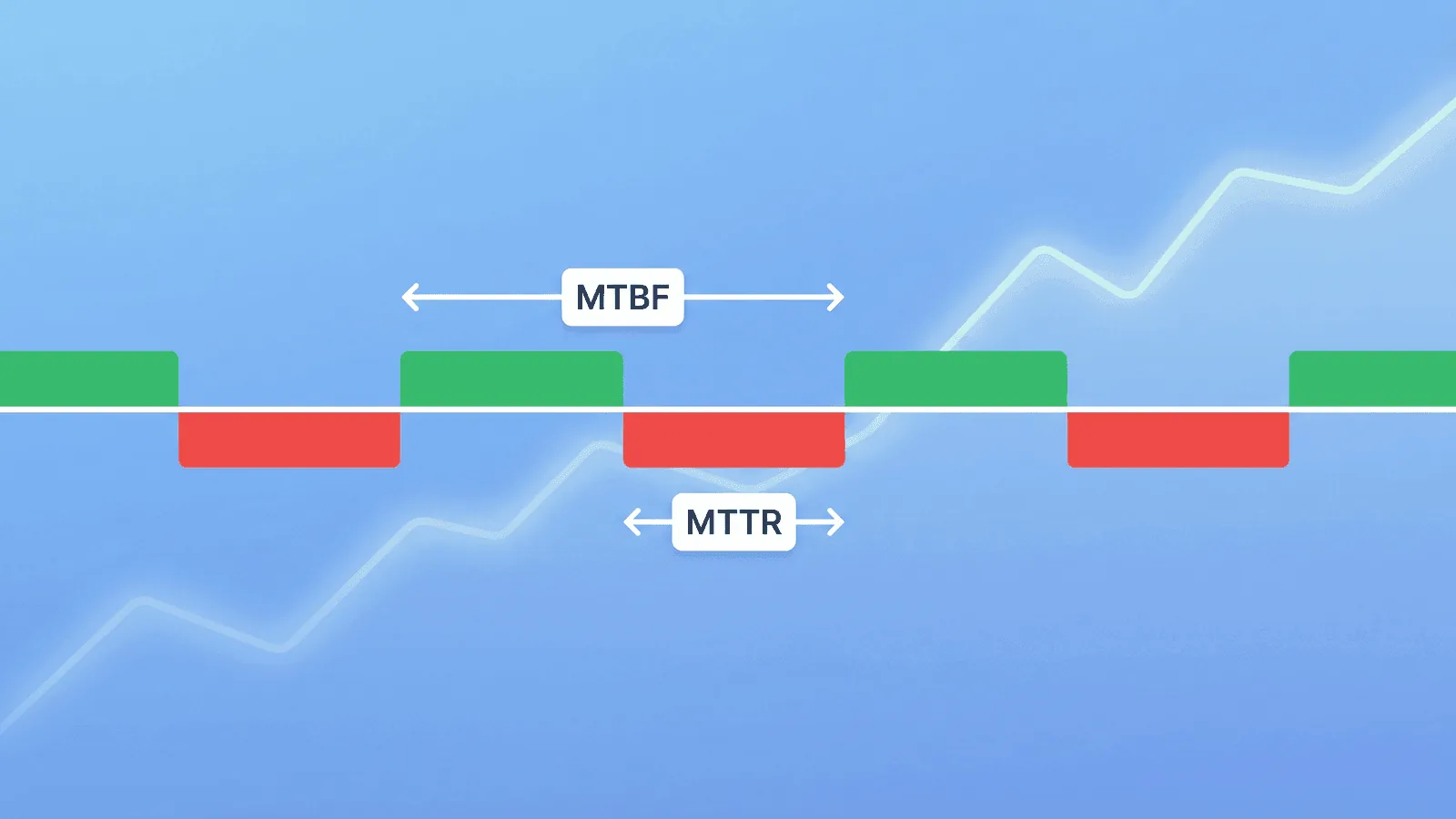
MTTR, MTBF, MTTF Explained: Reliability Metrics Every Team Should Track
MTTR, MTBF, and MTTF measure how fast you recover and how often things break. Learn what each metric means, how to calculate them, and why they matter.

How to Prevent Website Outages: A Proactive Monitoring Guide
Most outages are preventable. Learn the top causes of downtime and how to catch every one of them before your users do.

Monitoring for Startups: Set Up Reliability Before Your First 1,000 Users
You don't need a platform team to monitor your product. Here's the practical startup playbook — what to monitor, when, and how to grow into it.

What Is Uptime Monitoring? A Complete Beginner's Guide
Uptime monitoring explained: what it is, how it works, and why your website needs it. Simple guide for beginners.

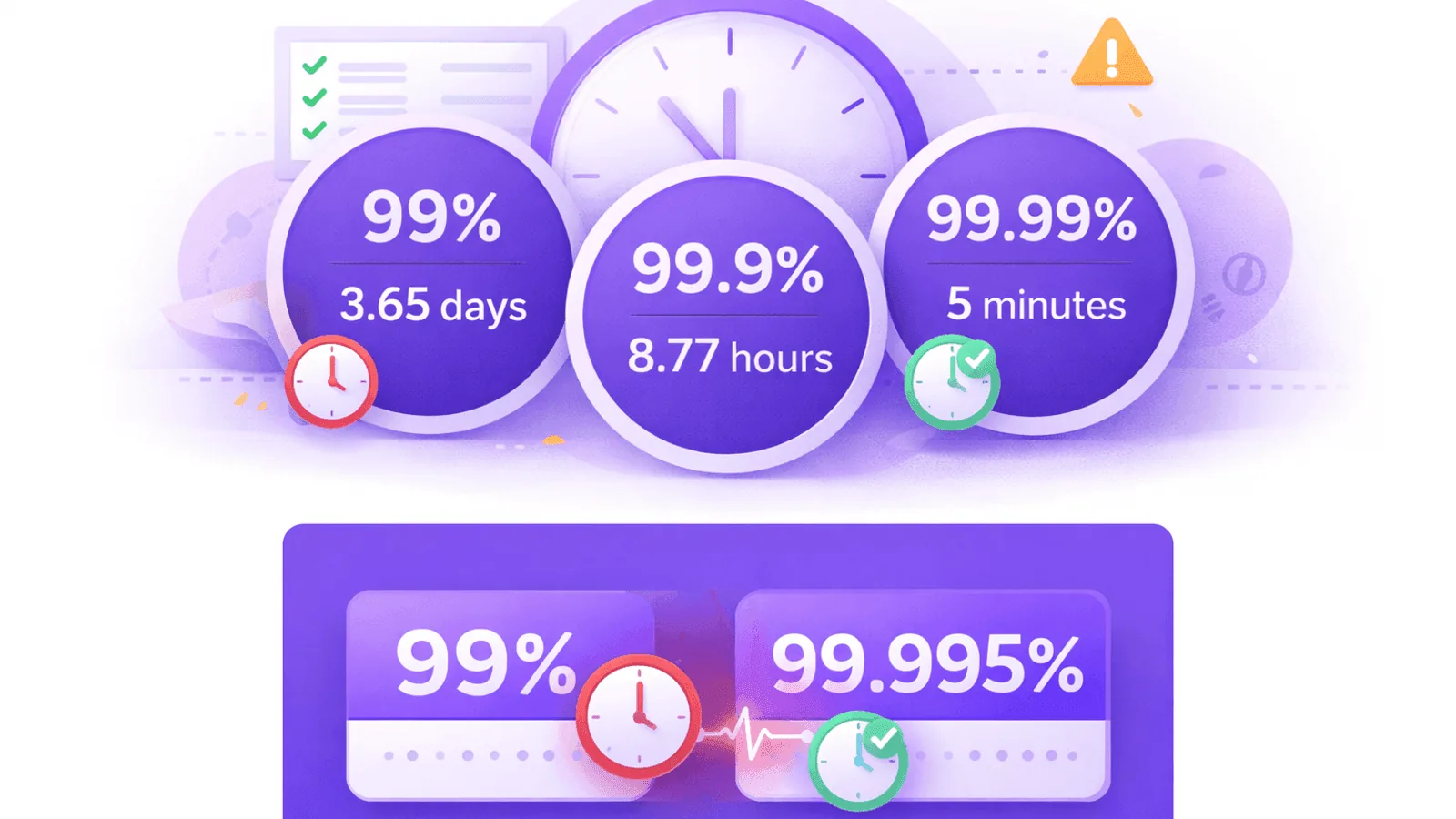
99.9% vs 99.99% Uptime: Downtime Per Month/Year Calculator
How much downtime do 99.9%, 99.99%, and 99.999% SLAs allow? See the exact minutes per month and hours per year for each availability tier, plus how to choose the right SLA target.

WordPress Uptime Monitoring: Keep Your Site Always Online
Monitor your WordPress site for downtime, slow performance, and plugin issues. A practical guide to uptime monitoring for WP.

Webhook Monitoring Guide: Detect Failed Deliveries Fast
Webhooks fail silently and break integrations for days. Learn to detect failed deliveries, processing gaps & permanent webhook errors before customers notice.

Cron Job Monitoring: Never Miss a Failed Background Task
Learn how to monitor cron jobs and background tasks. Catch silent failures before they cause data loss or angry customers.

Third-Party Dependency Monitoring: Watching What You Don't Control
Your uptime depends on services you don't control — payment processors, CDNs, auth providers, and cloud platforms. Learn how to monitor third-party dependencies before they take you down.

Multi-Region Monitoring: Why Checking From One Location Isn't Enough
Your site might be online in New York but down in Tokyo. Learn why multi-region monitoring catches outages that single-location checks miss — and how to set it up properly.
Calculate Website Uptime: Why 99.9% Isn't Enough
Learn to calculate website uptime, understand SLA percentages, and discover why that impressive 99.9% uptime guarantee still means hours of downtime every year.

API Uptime Monitoring & Health Checks Guide
Your API is the backbone of modern applications. Learn how to monitor API endpoints, set up health checks, and catch failures before your users do.

DNS Monitoring: Foundation of Website Reliability
Your site can't load if DNS fails. Learn why DNS monitoring catches issues other tools miss — and prevents the outages nobody sees coming.

Why Every SaaS Needs Uptime Monitoring (Day 1)
A practical guide for new SaaS founders on why uptime monitoring matters from launch day — and how to set it up in minutes.