
Graceful Degradation: Designing Systems That Fail Well
What graceful degradation means, how it differs from fault tolerance, patterns like fallbacks and circuit breakers, and how to monitor a degrading system.

Black-Box vs White-Box Monitoring: What's the Difference?
Black-box vs white-box monitoring compared — what each one sees, where each one fails, and why resilient teams run both. A practical guide with examples.

Chaos Engineering Explained: Breaking Things on Purpose
What chaos engineering is, how a controlled experiment works, the role of monitoring and blast radius, and how to start small without causing real outages.

DORA Metrics Explained: The 4 Keys to DevOps Performance
What the four DORA metrics measure — deployment frequency, lead time, change failure rate, and time to restore — why they matter, and how to track them.

The Four Golden Signals of Monitoring Explained
Latency, traffic, errors, and saturation — what Google's four golden signals mean, why they work, how to measure each one, and how to alert on them.

Incident Severity Levels: SEV1 to SEV5 Explained
What incident severity levels (SEV1–SEV5 / P1–P5) mean, how to define them, who they page, and how to classify incidents consistently under pressure.

RED vs USE Method: Monitoring Metrics Frameworks
RED (Rate, Errors, Duration) vs USE (Utilization, Saturation, Errors) — what each method measures, when to use which, and how they fit together.

How to Reduce MTTR and Recover from Incidents Faster
Every minute of downtime costs money. Learn the 5 levers that reduce Mean Time to Recovery and how monitoring shortens each one.
Post-Incident Monitoring: What to Watch After an Outage
The hours after an incident are the riskiest. Learn what to monitor during recovery to catch regressions and rebuild confidence.
How to Write an Incident Runbook That Works
Runbooks turn panicked debugging into calm execution. Learn how to write, structure, and maintain runbooks your on-call team will actually use.

Observability vs Monitoring: What's the Difference and Which Do You Need?
Monitoring tells you when something breaks. Observability tells you why. Learn the real difference and how to decide what your team needs.
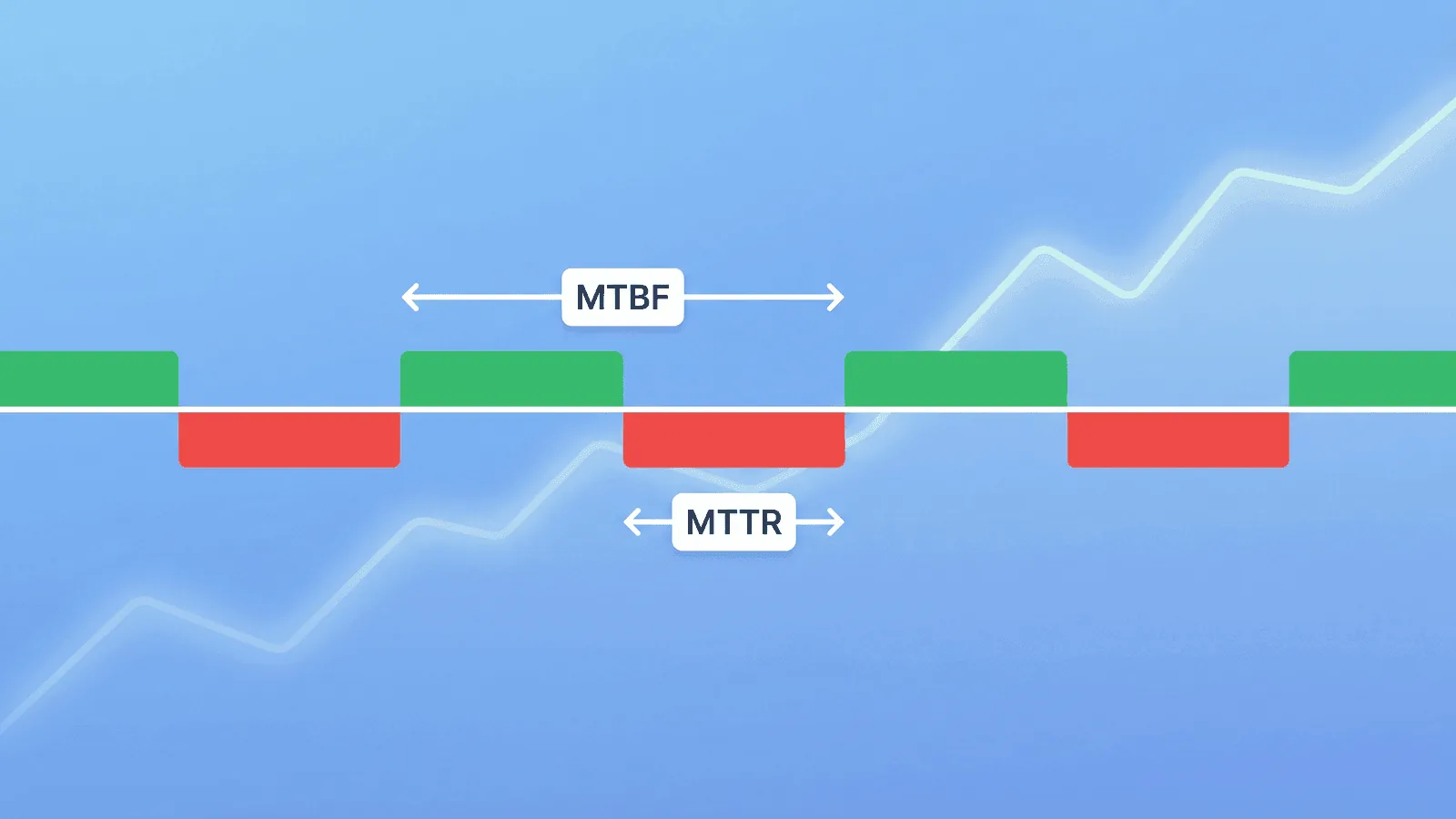
MTTR, MTBF, MTTF Explained: Reliability Metrics Every Team Should Track
MTTR, MTBF, and MTTF measure how fast you recover and how often things break. Learn what each metric means, how to calculate them, and why they matter.