
Chaos Engineering Explained: Breaking Things on Purpose
What chaos engineering is, how a controlled experiment works, the role of monitoring and blast radius, and how to start small without causing real outages.

DORA Metrics Explained: The 4 Keys to DevOps Performance
What the four DORA metrics measure — deployment frequency, lead time, change failure rate, and time to restore — why they matter, and how to track them.

Incident Severity Levels: SEV1 to SEV5 Explained
What incident severity levels (SEV1–SEV5 / P1–P5) mean, how to define them, who they page, and how to classify incidents consistently under pressure.
How to Create a Website Status Report (Template & Metrics)
Build a website status report stakeholders trust: which uptime, performance and incident metrics to include, a reusable template, and how to automate the data.
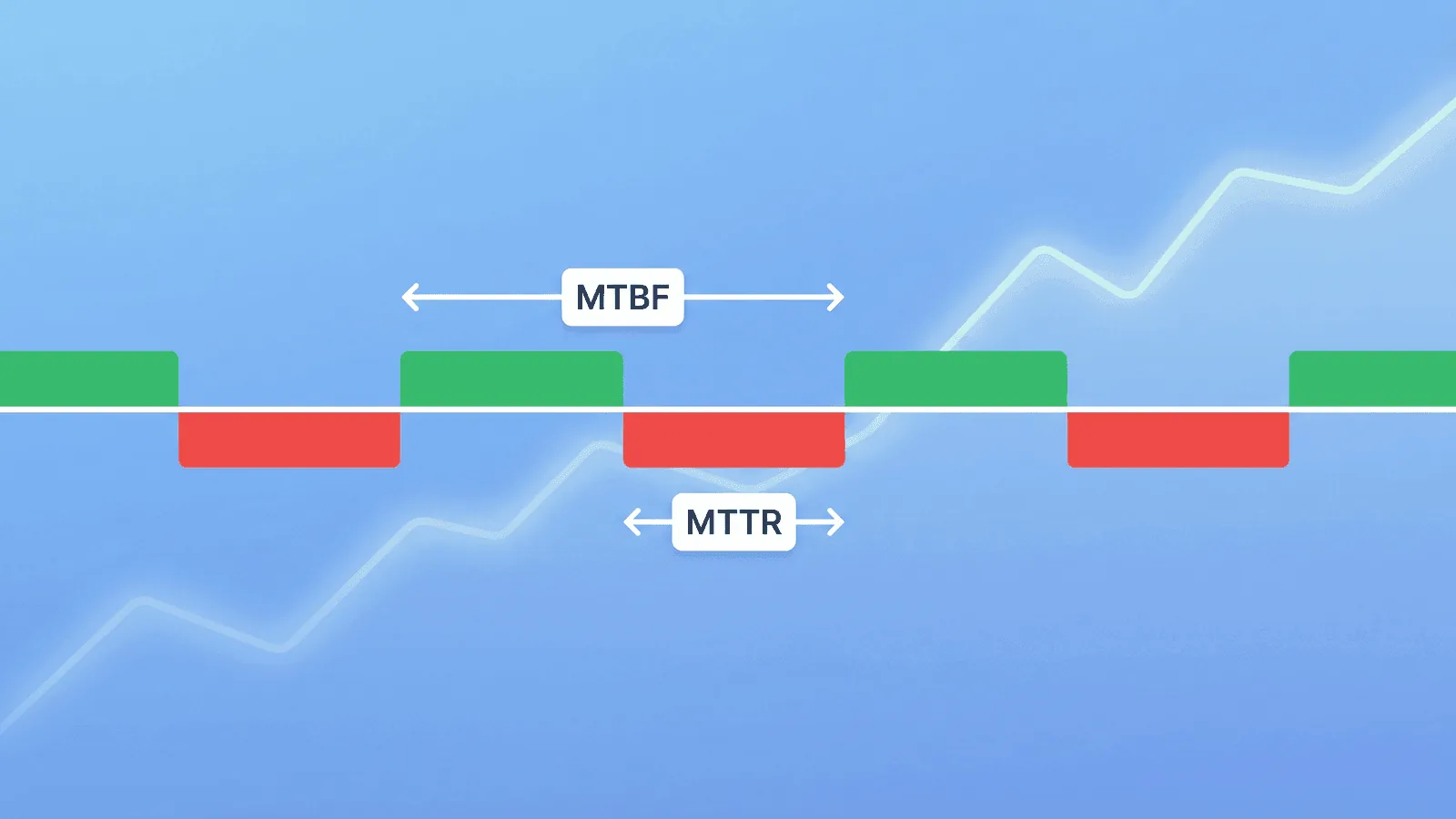
MTTR, MTBF, MTTF Explained: Reliability Metrics Every Team Should Track
MTTR, MTBF, and MTTF measure how fast you recover and how often things break. Learn what each metric means, how to calculate them, and why they matter.

Incident Post-Mortem Guide: Prevent Future Outages
Learn how to write effective incident post-mortems that prevent repeat failures. Includes a free template and real-world examples from engineering teams.